L’IA sort les personnes sourdes du monde du silence

Auteurice de l’article :

C’est une première mondiale. Un dictionnaire langue des signes-langue vocale vient d’être mis en ligne. Il est le fruit de travaux mêlant linguistique, reconnaissance faciale et intelligence artificielle.
En Belgique, la langue des signes est pratiquée par 4.000 personnes. Jusqu’alors, de par le monde, aucun dictionnaire ne lui était consacré, vers aucune langue vocale. Voilà quelques années, Laurence Meurant, directrice du Laboratoire de langue des signes de Belgique francophone à l’UNamur, et son équipe se sont mis à rêver d’un outil inspiré du principe de Linguee©. Celui-ci permettrait de comprendre et d’utiliser adéquatement les mots et les expressions ou les signes dans des contextes variés. En 2018, une équipe pluridisciplinaire composée de linguistes et d’informaticien·nes de l’UNamur a décidé de relever ce défi scientifique et technologique. Leurs efforts ont porté leurs fruits : le tout premier dictionnaire langue des signes de Belgique francophone – français, que l’on peut interroger gratuitement dans les deux langues, vient d’être mis en ligne. C’est une première mondiale.
Soutenu financièrement par le Fonds Baillet Latour, il a été conçu à l’intention des familles entendantes avec un·e enfant sourd·e, des locuteurices d’une langue signée qui doivent passer au français, plus largement de toute personne ayant besoin occasionnellement de faire le pont entre français et langue des signes, et aussi à l’intention des classes bilingues, lesquelles ont initié ce projet.
“Jusqu’à la naissance de ce premier dictionnaire langue des signes-français, c’étaient nous, enseignant·es, qui devions jouer le rôle de répertoire pour les enfants. La langue des signes ne s’écrivant pas, nous devions réaliser des vidéos présentant le signe d’un nouveau mot, le mettant en contexte, et joindre ces vidéos par QR code aux feuilles distribuées en classe. C’était un travail monumental”, explique Magaly Ghesquière, coordinatrice des classes bilingues langue des signes – français et enseignante à la Communauté scolaire Sainte-Marie à Namur. Là, de petits groupes d’enfants sourd·es sont insérés dans des classes d’enfants entendant·es de l’enseignement général. “Pour les enfants sourd·es, le dictionnaire permet, par exemple, la compréhension quasi immédiate d’expressions complexes dans des romans écrits en français. Pour les enfants entendant·es, en les aidant à acquérir les signes nécessaires pour converser avec leurs camarades sourd·es, il est la clé qui ouvre la porte d’un autre monde.” Celui du silence.

Deux sens linguistiques
Concrètement, comment fonctionne ce dictionnaire ? Le matériel nécessaire se compose d’un ordinateur, d’une tablette ou d’un smartphone, équipé d’une caméra et connecté à Internet avec un bon débit. Ensuite, il faut rejoindre le site web du dictionnaire.
Pour qui veut connaître le signe correspondant à un mot français, il suffit d’introduire ce dernier pour qu’une vidéo s’anime, montrant une personne effectuant le signe. Des exemples permettant de voir le signe utilisé dans son contexte sont une précieuse aide. “En effet, en langue des signes comme dans toutes les langues du monde, il n’y a pas de transposition directe d’un mot en un autre. Le contexte joue une part importante”, précise Pre Laurence Meurant.
Le dictionnaire est également opérationnel dans l’autre sens linguistique. Face à la webcam, en positionnant son visage dans le cercle en pointillés, on saisit un signe et la plateforme affiche sa traduction en français. “Pour 80 % des requêtes, le signe correct est dans le top 5 proposé par l’intelligence artificielle (IA)”, se réjouit Jérôme Fink, doctorant en informatique (UNamur), cheville ouvrière de ce projet depuis 5 ans. Une liste de suggestions d’usage du signe, sous forme de vidéos, enrichit et affine la recherche.
Un squelette numérique
“Passer du français à la langue des signes, c’était déjà un fameux défi technique. Passer de la langue des signes au français fut bien plus complexe encore”, explique Benoît Frénay, professeur au sein de l’institut NADI (Namur Digital Institute) et spécialiste en intelligence artificielle.
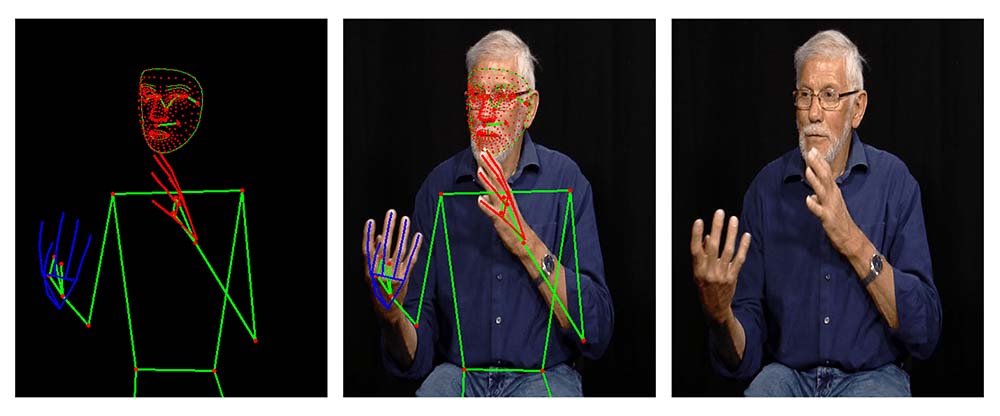
En effet, d’une part, chaque signeur·se est unique. Certain·es enchaînent les mouvements plus rapidement que d’autres, plus aguerri·es. Tous et toutes ont une morphologie particulière. D’autre part, chaque vidéo est unique, avec sa propre luminosité, avec des couleurs de vêtements et de peaux particulières. Chacun de ces paramètres complexifie la tâche de l’IA.
“Pour l’aider, nous avons collé sur chaque signeur·se, de façon informatique et automatique, une sorte de squelette numérique composé de points placés sur les éléments corporels utilisés en langage des signes : menton et bouche, contours du visage, commissure des yeux, mais aussi sur ses coudes, ses mains, ses doigts”, précise Benoît Frénay. Grâce à ce système, l’IA connaît, à chaque moment, la position de chaque point corporel impliqué dans le signe à reconnaître.
20 années de travail de fourmi
Pour alimenter cette intelligence artificielle et l’entraîner, les chercheur·ses se sont basé·es sur un riche corpus de 36h37 de vidéos de signes annotées et analysées une par une par des signeur·ses. Il comprend quelque 180.000 signes, représentant 4.600 signes répétés de multiples fois par une centaine de signeur·ses. Un travail de bénédictin qui a occupé les linguistes de l’UNamur pendant pas moins de 20 ans ! “Une base de données suffisamment large était primordiale pour que l’IA puisse parvenir à reconnaître un signe devant n’importe quelle webcam”, explique Pre Laurence Meurant.
“Pour que l’IA puisse identifier un signe et transmettre sa traduction française, il lui fallait s’entraîner sur un minimum de 30 occurrences de chaque signe. Dans le corpus, c’est le cas pour pas moins des 750 signes les plus couramment utilisés par les signeur·ses. Soit 35% de leur lexique de base. Dans le sens français vers langue des signes, la tâche était bien plus aisée et quelque 2.100 signes de noms communs et de verbes sont d’ores et déjà accessibles”, ajoute Pr Anthony Cleve, co-pilote de ce projet avec Pre Laurence Meurant.
Une amélioration continue
Les prochaines années verront cette banque de données s’enrichir et l’IA se bonifier. “Un monitoring des erreurs sera mis en place de telle sorte que le système de reconnaissance permettant de détecter le signe de l’utilisateurice, soit constamment amélioré, affiné. Cela permettra non seulement de fournir des traductions encore plus précises et justes, mais aussi d’enrichir le corpus”, poursuit-il.
Pour garantir l’intuitivité du site, des signeur·ses, des expert·es et des enseignant·es ont été impliqué·es à différents stades du développement du projet. Il en résulte un outil performant, facile d’usage, accessible gratuitement partout ainsi que par tous et toutes. De quoi favoriser l’inclusion des personnes sourdes et malentendantes dans la société.
Une histoire, des projets ou une idée à partager ?
Proposez votre contenu sur kingkong.
à découvrir aussi

Go with the flow of digital creativity, la Grande région créative est en marche !

Créativité numérique en Wallonie et à Bruxelles : derrière la vitrine de l’innovation, les inégalités de genre persistent

wake! Tour 2025, la Wallonie créative accélère en mode international
