‘Have I been trained’, or consent to AIs

Article author :

En apparence, c’est un moteur de recherche qui permet aux artistes de savoir si leur travail a été utilisé pour entraîner des intelligences artificielles génératives d’images. En arrière-plan s’ouvre le débat sur le consentement à ces technologies et le bien-fondé du mécanisme de propriété intellectuelle. Plongée dans “Have I been trained” avec Mathew Dryhurst, son co-créateur.
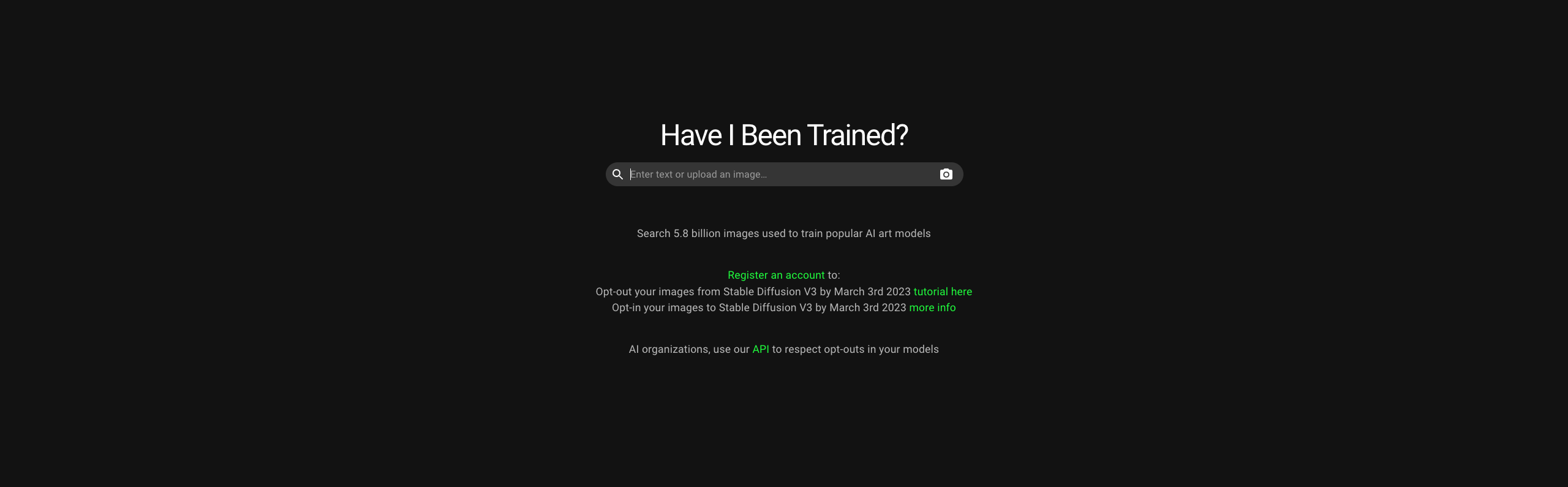
On connaissait “Have I been pwned“, un moteur de recherche qui permet de savoir si son adresse email a été corrompue. Voici “Have I been trained”, un moteur mis en place par le duo d’artistes Holly Herndon et Mathew Dryhurst et qui propose aux artistes de rechercher – via texte ou image – si leur travail a été utilisé pour entraîner des intelligences artificielles (IA) de génération d’images telles que Dall·E. Si tel est le cas, l’utilisateur peut s’identifier et réclamer que cette donnée ne soit plus utilisée dans le futur pour entraîner des IA – en tout cas, par les organisations qui s’engagent à respecter cette demande. “Nous avons trouvé un accord avec Stability pour qu’ils honorent les requêtes faites sur notre site et il est possible de se retirer de Stable Diffusion v3”, se félicite le chercheur et artiste Mathew Dryhurst, qui affirme être en discussion avec d’autres entreprises. “Nous ne pouvons pas garantir que toutes répondront favorablement, mais nous sommes optimistes sur le fait que de plus en plus d’organisations nous rejoindront.”
Pour obtenir ces informations, le duo s’appuie sur LAION-5B, une base de données publique de 5,85 milliards d’image CLIP, un modèle développé par OpenAI et qui permet d’associer image et texte. Portée par l’organisation à but non lucratif Laion, dont l’objectif est de “libérer la recherche en machine learning”, la base de données est utilisée par “de nombreux services d’images populaires comme Stable Diffusion”, présente Mathew Dryhurst.
Les résultats obtenus via “Have I been trained” sont donc significatifs, mais parcellaires. “Nous sommes ouverts à l’exploration d’autres bases de données, fait savoir le chercheur. Mais pour le moment, de nombreuses organisations n’ont pas rendu publiques celles qu’elles utilisent pour leurs modèles.”
La propriété intellectuelle, mal adaptée à l’ère de l’IA
Derrière ce site à l’apparence simple, c’est la notion de consentement à l’entraînement des IA que défendent Mathew Dryhurst et Holly Herndon. Une problématique sur laquelle iels travaillent, notamment en s’adressant directement aux entreprises d’IA, depuis 2017 – “longtemps avant que les gens ne s’en préoccupent”, souligne l’artiste.
La tâche est loin d’être simple. Rendu urgent par les récentes avancées et le succès phénoménal des dernières IA génératives, le problème prend racine dans le fonctionnement même du web, décrit Dryhurst dans un article sur Art Review. Pour le duo, c’est tout le mécanisme de propriété intellectuelle qu’il faut remettre en cause. Il n’était déjà pas adapté pour Internet, il l’est encore moins à l’ère des IA génératives, ou de ce que le duo appelle le spawning : créer indéfiniment de nouvelles œuvres à partir de données d’entraînement, un processus “relativement plus significatif que la pratique du sampling ou du collage du 20ème siècle”, estime Dryhurst.
Devant l’ampleur de la tâche, chaque chose en son temps, tempère l’artiste. “Nous nous concentrons à établir une autorité et une propriété sur les données d’entraînement, parce que nous estimons que dans un monde assisté par IA tout média est une forme de data d’entraînement, pose-t-il. Et nous espérons que les lois et les politiques vont commencer à digérer à quel point il s’agit d’une affaire importante.” À terme, Mathew Dryhurst estime qu’il pourrait être bénéfique pour la communauté IA comme pour la communauté des artistes d’obtenir des données consenties. “Il est encore tôt et c’est une bonne chose que le public débatte sur comment les choses doivent être, pense-t-il. J’aimerais éviter ce qu’est un monde sans consentement, projette-t-il dans son article. Lorsque le consentement est absent, de belles relations et connexions sont entravées plutôt que d’être nourries.”
Une approche pragmatique ?
Du côté des artistes nouvellement confronté·es aux IA, l’approche ne fait pas l’unanimité. L’initiative a reçu un accueil plutôt mitigé, reconnaît Dryhurst. Dans le milieu de l’art contemporain, où évolue le duo, on félicite les artistes de “rendre transparent les mécanismes de la donnée d’IA et de proposer de nouvelles perspectives pour que les artistes puissent espérer construire de nouvelles économies autour de leurs données”, rapporte-t-il. D’autres communautés, en particulier celle de l’illustration commerciale ou celle de l’art conceptuel, ont été plutôt critiques. “Leur position est de dire que tous les modèles d’IA auraient dû être basés sur le choix depuis le début et iels pensent que notre approche pragmatique ne va pas assez loin. Sur le principe, je suis d’accord avec elleux, pose l’artiste. Je pense qu’avec le temps, on comprendra que nous voulons toustes la même chose.”
Loin des débats enflammés sur la place des artistes dans la société et leur potentiel remplacement ou non par des algorithmes, le duo reste concentré. “Je pense que le débat “IA contre artistes” a pris de l’importance, en grande partie parce qu’il est le plus dramatique et qu’il se prête au genre de tribalisme simple et d’alarmisme qui prospère en ligne. Ces débats trop simplistes sont devenus une nouvelle forme de divertissement, mais je me concentre davantage sur la création de moyens permettant aux artistes de gagner leur vie et d’expérimenter de nouveaux types d’art et de relations dans un monde où l’IA joue un rôle de plus en plus important. Le développement de l’IA va devenir de plus en plus fou et étrange au cours des prochaines années, et je contrebalance mon intérêt pour cette question par un engagement à bien faire les choses pour les personnes dont les données influenceront cela.”
A story, projects or an idea to share?
Suggest your content on kingkong.
also discover

Go with the flow of digital creativity, The Greater Creative Region is on the move!

From Belgium to Japan, the new territories of creative digital creativity

Stereopsia, the key European immersive technologies hub
